Throughput times
Applies to: CELONIS 4.6 CELONIS 4.7
Description
These examples show various ways of throughput time calculations in PQL.
Throughput time calculations are vital in powerful process mining applications. In the following, different kinds of throughput times and possible calculations using PQL are presented:
Throughput times per case: Learn how to calculate throughput times inside a case, e.g. the time from the start of each case to the end of the case or between specified activities within a case.
Throughput times between activities: Learn how to calculate the throughput times between consecutive activities inside a case.
Throughput times over multiple cases: Learn how to calculate throughput times over multiple cases, e.g. the throughput times of orders consisting of multiple cases.
Throughput times per case
Throughput time calculations on case level can be solved using CALC_THROUGHPUT. It is usually used together with REMAP_TIMESTAMPS, which adds many options for calendar specifications.
[1] Here, the case throughput time from the first activity to the last activity of each case is calculated in days. As DAYS is specified as the time unit, the minutes of the input timestamps are ignored.
|
[2] In this example, the throughput time between the last A-activity and the first C-activity of each case is calculated.
|
[3] If the case throughput time should be calculated in days, but the hours should not be ignored, we can calculate the throughput times in hours first and then divide the result by 24 (hours per day).
|
[4] In this example, only weekdays should be counted towards the case throughput time, ignoring Saturdays and Sundays. This can be done using the WEEKDAY_CALENDAR in REMAP_TIMESTAMPS.
|
[5] The activity table of this example contains several Error-activities. This example shows how to calculate the throughput time between the case start and the first Error-activity of each case. This can be done by mapping all Error-activities (those are all activities starting with Error) to a common string (ErrorActivity in this example) using a CASE WHEN in the last argument of the CALC_THROUGHPUT function. As the result of this CASE WHEN is now taken as the activity column to be used in CALC_THROUGHPUT, the ErrorActivity can now be used inside the
|
Throughput times between activities
Throughput times between consecutive activities can be calculated using SOURCE and TARGET, usually combined with a DateTime Difference function or REMAP_TIMESTAMPS. The Process Explorer and the Variant Explorer use this approach to calculate the throughput time for each edge in the graph.
[6] This simple example shows how to calculate the number of days between consecutive activities of each case using SOURCE/TARGET and DAYS_BETWEEN.
|
[7] Here, we use REMAP_TIMESTAMPS on the SOURCE/TARGET timestamps and subtract those values to get the difference between consecutive timestamps in days. By using the WEEKDAY_CALENDAR option, we only take weekdays into account, meaning that Saturday and Sunday do not count towards the time difference.
|
Connection to the Process Explorer
The SOURCE and TARGET functions are used in the Process Explorer and Variant Explorer to calculate the edge KPIs, as shown in the following examples.
[8] This example shows the query that is used to calculate the average throughput time between activities in days. Therefore, the difference of the two timestamps is first calculated in SECONDS and then converted to DAYS by dividing the difference by 60*60*24. Finally, the result is rounded. The corresponding Process Explorer would look like this:
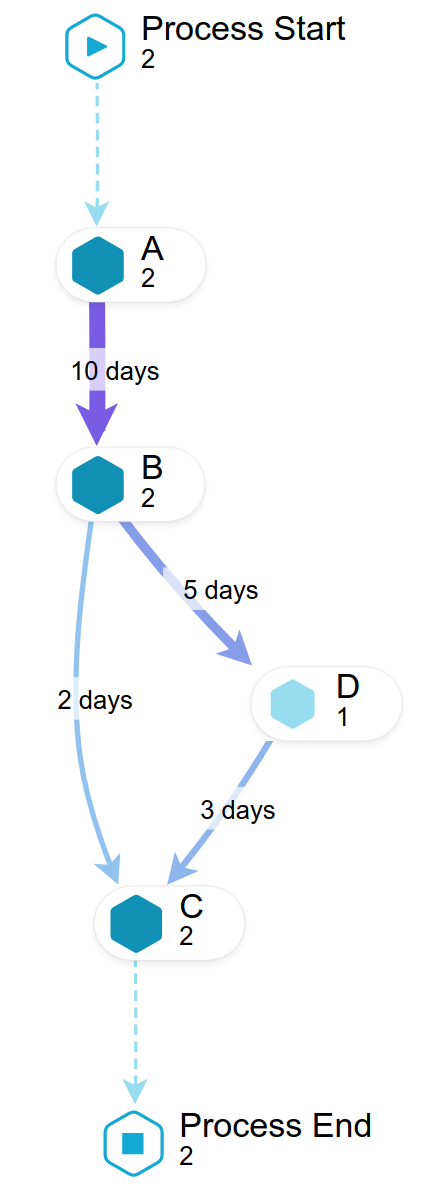 |
|
[9] The query below calculates the average number of days between consecutive activities, with activity 'B' being ignored. This is the query that is used when activities are ignored using the 'Eye' icon in the Process Explorer.
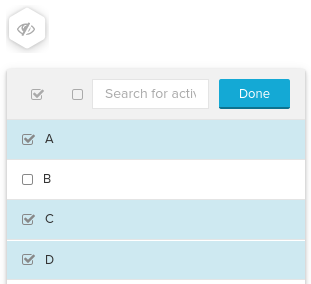 |
The corresponding Process Explorer looks like this:
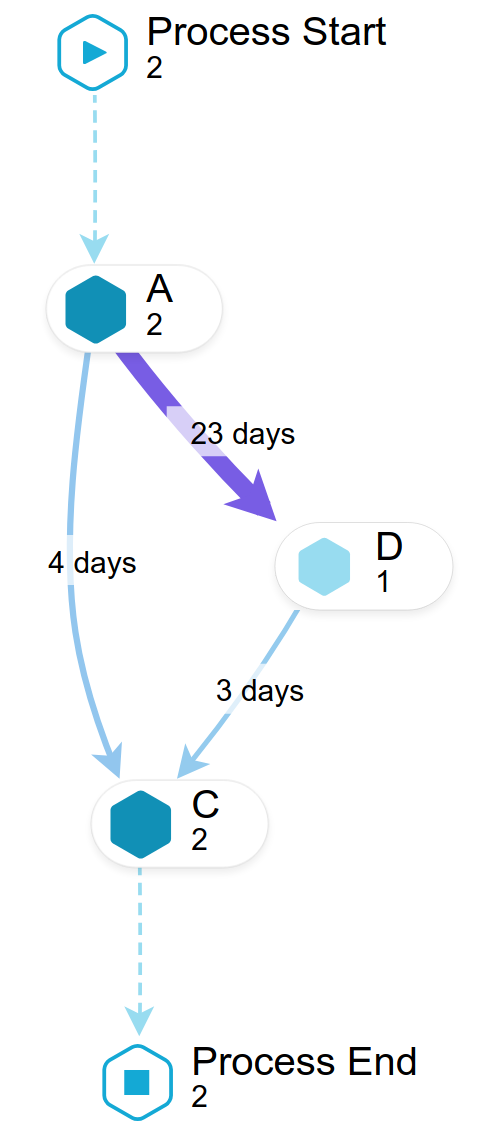 |
|
Throughput times over multiple cases
Throughput times over multiple cases can be calculated using PU_MIN and PU_MAX, combined with a DateTime Difference function or REMAP_TIMESTAMPS. This can be used to calculate the time range covered by all cases that are grouped together based on a certain property.
[10] This example shows how to calculate the throughput time of each order. An order consists of one or more order items, which are the cases in the example. The throughput time of an order is the time difference between the first activity among all cases related to that order and the last activity among all cases of that order. We can use PU_MIN and PU_MAX to get the smallest (earliest) and largest (latest) timestamps related to each order and compare those using DAYS_BETWEEN.
|
[11] This example shows how to calculate the average throughput time of an order, using an AVG around the query that calculates the throughput time of each order. Instead of using DAYS_BETWEEN like in the previous example, we can also use REMAP_TIMESTAMPS again to get the number of days between two timestamps. As explained above, REMAP_TIMESTAMPS only counts full days with the DAYS specification. Using REMAP_TIMESTAMPS allows you to take calendars into account, as already shown above:
|