DECISION_TREE
Applies to: CELONIS 4.3 CELONIS 4.4 CELONIS 4.5 CELONIS 4.6 CELONIS 4.7
Description
Create a decision tree, learn classification rules based on training data, and use it to classify new data rows.
Like other machine learning functions (such as KMEANS or LINEAR_REGRESSION), the DECISION_TREE function consists of two steps.
The first step consists of training the decision tree model. This will learn the classification rules of the decision tree (see the Wikipedia article on decision tree) based on the provided training data. In this step, the user can specify which columns the model should use, and on which subset of the data the system should be trained on. Additionally, an extra max_depth parameter can be provided in order to avoid overfitting to the training data.
In a second step, once the model is trained, the user can use it to classify new rows based on the model input columns.
Syntax
DECISION_TREE ( TRAIN_[FILTERED_]DT ( [ EXCLUDED ( table.exclude_column, ... ), ] INPUT ( table.input_column, ... ), OUTPUT ( table.output_column ) [, max_depth ] ), PREDICT ( table.predict_column, ... ) )
TRAIN_DT: Constructs the decision tree, while ignoring any given filter(s). Authorization objects are still respected.TRAIN_FILTERED_DT: Constructs the decision tree, filtering the training data with current filters.EXCLUDED: One or more dimension columns (columns that are not aggregations) that should be used as grouping columns for theINPUTcolumns of the model training. These columns will be ignored by the training algorithm and will not be part of the trained model, unless the columns are also specified in theINPUT.INPUT: One or more columns, which is used to train the model.OUTPUT: One column containing the labels associated to each row that the model should train upon.max_depth: This specifies the maximal depth allowed for the learned tree, this can be used to prevent overfitting. The default value ismax_depth=0, which means no limit will be set on the depth of the tree.PREDICT: One or more columns, which the rules of the trained decision tree should be applied upon. The number ofPREDICTcolumns must be the same as the number ofINPUTcolumns. The columns should be semantically the same as the ones provided as the modelINPUTparameter, for the results to make sense. Any mix of FLOAT and INT columns inINPUTandPREDICTwill return meaningful results. Although other mixes of data types will be accepted by theDECISION_TREEfunction, the results should not be used.
All columns in TRAIN_DT have to be joinable. The columns in PREDICT do not have to be joinable with the columns in TRAIN_DT.
The input of the model training is regarded as an independent sub query. This means if an aggregation is used, it is independent of the dimensions defined in the rest of the query. This also means that the columns within TRAIN_DT have to be joinable, but they do not have to be joinable with the columns used in the rest of the query.
NULL handling
If a row contains a NULL value, the value is ignored and does not affect the model.
If a
PREDICTrow contains a NULL value, the result for that row will be NULL.
Filter behavior
Standard Decision Tree
If rows of a column are filtered, it does not affect the decision tree, as long as the decision tree model is not trained on aggregation results. This means independent of filters and selections, the underlying model stays the same. If some of input data of a model should be restricted, a CASE WHEN statement can be used to map the values that should be ignored to NULL.
If a model is trained on results of an aggregation it still changes with the filtering because the result of the aggregation is affected by the filtering.
Filtered Decision Tree
If a filter or selection changes, the model is retrained and the resulting function adopts to the new of view of data. This may have a large impact on performance.
Result
DECISION_TREE splitting rules are constructed to reduce the entropy within subsets of the data created at each splitting point.
Examples
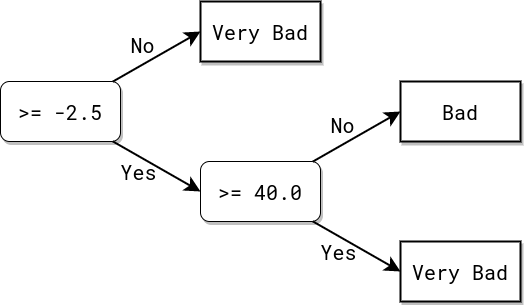
In this example two unconnected tables are used. The There no
|
[2]
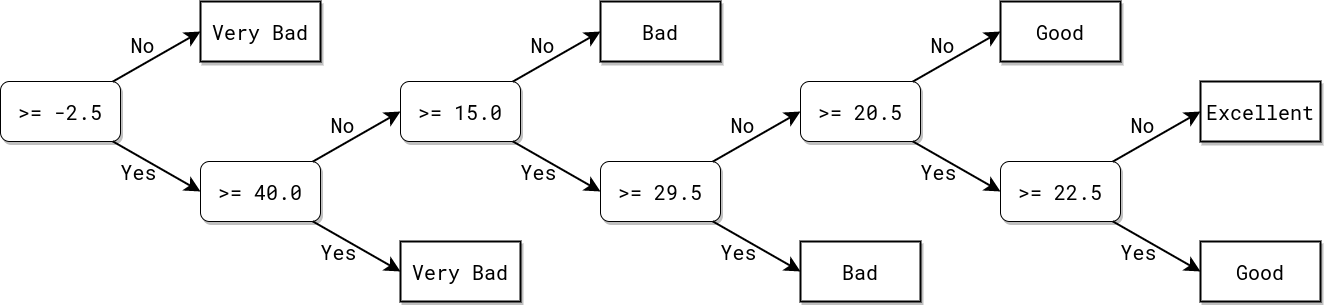
In this example a FILTER is applied to the training input data, meaning only data points with value below 30 are used in the model training. This restriction changes the prediction. Note that the current or any given filter is only applied in the The
|
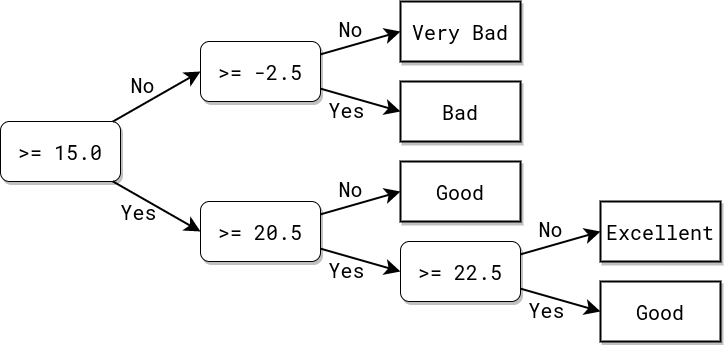
In this example a non-default value for
|